LLM-based semantic maps
Most semantic studies using word embeddings don’t distinguish between different words and word-senses that share a spelling. Can we use contextual word embeddings to explicate and visualize these automatically? And which language models produce the most illuminative sense distinctions?
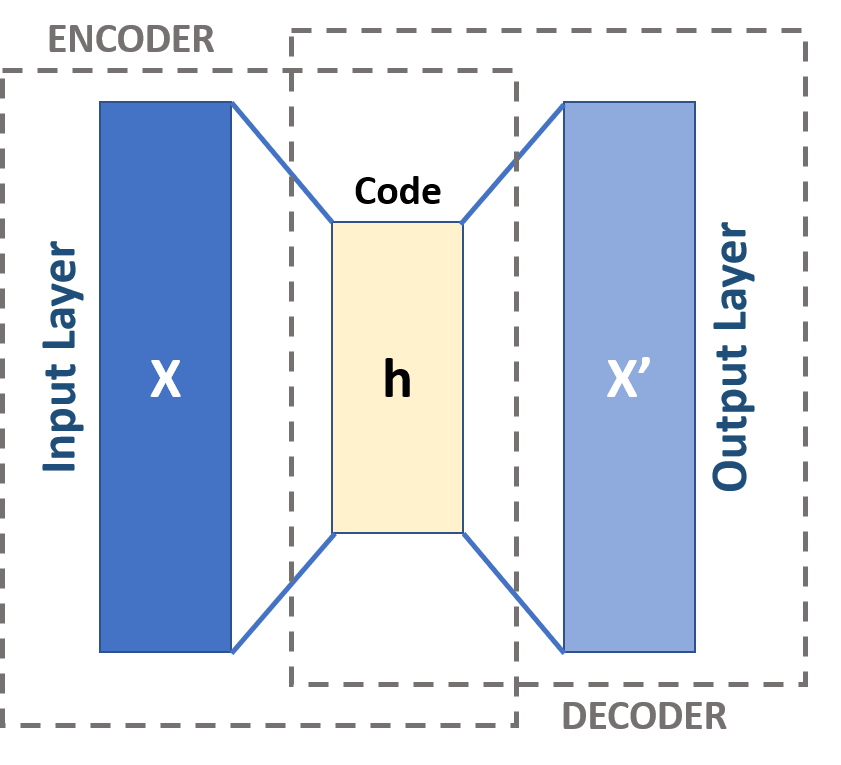
Self-supervised approaches to abstractive summarization
Humans judge summaries based on how much key information they capture, not whether they match someone else’s summary word for word. Can we treat summarization as autoencoding rather than supervised text generation?
Word embeddings as Natural Semantic Metalanguages
If we constrain a word/token embedding’s features to represent semantic primes in sequence, how much information could it capture compared to an unconstrained word embedding of equivalent dimension? What could such a mathematical metalanguage tell us about NSM theory?
Historical simulation language model training
Human speakers gain a deeper understanding of a language by encountering earlier forms of it. But most languague models pretrain only on internet-age texts. If we train a language model in a historically reconstructed fashion, starting with renaissance texts and moving forward epoch by epoch, how would it perform differently on modern texts?